
Studio Tarantelli > Articoli Informatica > Big Data > La diagnosi del coronavirus con l'aiuto del Machine Learning
La diagnosi del coronavirus con l'aiuto del Machine Learning
Il fenomeno del coronavirus sta affliggendo tutto il mondo ed ha portato la comunità scientifica a valutare diversi approcci nella diagnosi, utilizzando prevalentemente il tampone nasale e faringeo, che inizialmente quando si è diffusa la pandemia necessitava di diversi giorni per averne i risultati.
L’intelligenza artificiale spesso conosciuta dalle persone per aspetti legati alla vita quotidiana (vedi riconoscimento vocale, facciale, etc) è uno strumento che oggi risulta fondamentale in tutti i campi, da quelli finanziari, statistici, business, medici, ingegneristici, etc., ed è composta da diverse branche, tra cui il Machine Learning o apprendimento automatico, che permette inizialmente di acquisire una base di dati composta da diverse tipologie, come testo, numeri, immagini, video, biologici, etc. e farle apprenderle (training) a delle macchine affinchè possano classificare e quindi identificare un problema (o il quesito a noi caro) per fornire un risultato, basato su una certa affidabilità statistica.
La materia è molto complessa, ma non è mia intenzione entrare nei meandri dei tecnicismi, anzi cercherò di non parlarne, ma il mio scopo è solo quello di mostrare un approccio basato su questa metodologia che è stata di grande supporto in Cina proprio per l’aiuto nella diagnosi del Covid-19.
Approccio basato sulla Tomografia Computerizzata (TC)
In questo articolo vorrei soffermarmi su uno degli approcci possibili nella diagnosi del coronavirus basato sulla tomografia computerizzata.
La malattia del COVID-19 ha mostrato febbre, tosse ed affaticamento respiratorio durante le prime fasi ed i pazienti presentavano situazioni anomale nelle loro immagini toraciche rilevate mediante la tomografia.
Gli esperti clinici hanno avuto bisogno anche di immagini TC del polmone per diagnosticare il coronavirus nelle prime fasi, con sistemi di visione computerizzata per supportare le applicazioni mediche ed aumentare la qualità dell'immagine, la segmentazione degli organi e la classificazione delle strutture degli organi, etc.
Preparazione e reperimento dei dati
Un approccio tecnologico come il Machine Learning necessita di una accurata base di dati che permette dopo una selezione puntuale degli stessi, di poter eseguire l’apprendimento e successiva analisi, al fine di avere risultati concreti e non fuorvianti.
In parole povere lo scopo è quello di prendere delle immagini derivanti dalle tomografie computerizzate di persone sane e malate, ottimizzarle e rendere questi dati uniformi per una valutazione identificando un indice di affidabilità. Successivamente memorizzare queste informazioni e sottoporre alla "macchina intelligente" nuove immagini per una valutazione clinica iniziale e ricevere un risultato: sano o malato! E' utile vero? Ovviamente il tutto supportato da valutazioni cliniche, ma vediamo come è stato fatto e come hanno utilizzato le immagini!
Le fasi in questo studio sono molteplici e diversi sono stati i team che hanno sviluppato approcci poi integrati.
Uno di questi ha scelto un set di dati che comprendeva inizialmente un totale di 618 immagini, di cui 219 immagini di 110 pazienti con COVID-19, 224 immagini di 224 pazienti con polmonite virale influenzale-A e 175 immagini di 175 persone sane.
Gli algoritmi di machine learning sono molteplici, solo per citarne qualcuno a solo titolo di elenco non esaustivo: classificazione, clustering, regressione, alberi decisionali, foreste casuali, etc.
La metodologia di machine learning utilizzata in questo studio è stata la classificazione delle immagini prese dalla tomografia computerizzata, mediante un modello di apprendimento profondo tridimensionale che ha raggiunto una precisione di classificazione complessiva dell'87,6%. L’apprendimento profondo (deep learning) è un sistema basato per segmentare e quantificare le regioni infette sulle immagini TC toraciche. E’ come immaginare di fare degli ingrandimenti ad altissima risoluzione (zoom) delle immagini in tre dimensioni, suddividerle in zone ed identificare quelle infette in maniera più precisa.
Un altro approccio ha utilizzato 249 pazienti COVID-19 e 300 nuovi pazienti COVID-19 per l’integrazione e convalida del loro studio con un coefficiente di “somiglianza” pari al 91,6%.
Per dare una idea del vantaggio in termini di tempo nell’aiuto della diagnosi, basti pensare che il normale sistema di delineazione richiedeva spesso da 1 a 5 ore, mentre con il loro sistema proposto ha ridotto il tempo a quattro minuti.
I risultati hanno mostrato che il metodo proposto potrebbe essere usato per diagnosticare il coronavirus come sistema di supporto a quelli classici.
Difficoltà dei dati
Questo approccio se applicato su di un singolo macchinario che esegue la tomografia computerizzata risulta più semplice, ma in un periodo dove il tempo è una discriminante fondamentale nel salvare la vita di una persona, è stato realizzato su diversi macchinari della regione cinese dello Zhejiang, che ovviamente hanno differenze tecniche e non solo, portando ad una ulteriore difficoltà nella ricerca di dati corretti da far processare e quindi “memorizzare”.
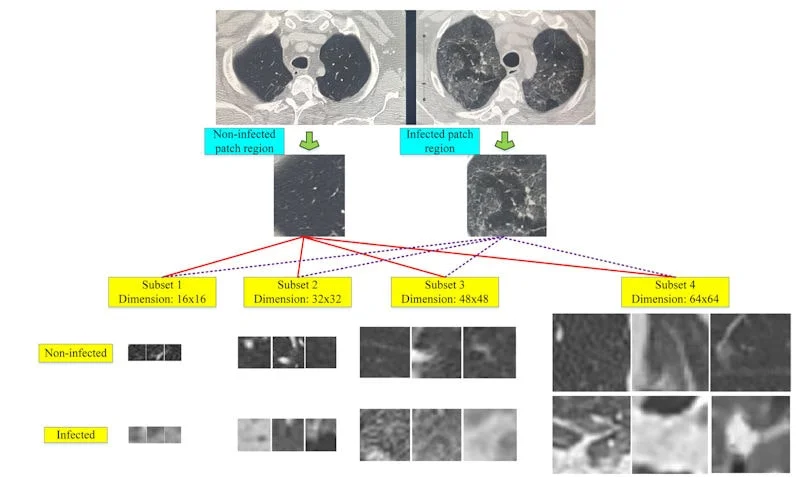
Questa situazione ha reso difficile il processo di classificazione, perché alcuni livelli di grigio in un'immagine TC rappresentavano le aree infette da coronavirus e gli stessi livelli di grigio in un'altra immagine TC rappresentavano le aree non infette, come evidenziato nella seguente immagine.
Ovviamente il problema è stato risolto con non poche difficoltà e con l’ausilio di tecniche di acquisizione, trasformazione, suddivisione ed estrazione che hanno richiesto convalide incrociate di dati fino a 10 volte rispetto al caso in cui le immagini fossero tutte pervenute da una stessa macchina.
Per valutare il metodo proposto sono state utilizzate cinque diverse metriche di valutazione, che sono sensibilità (SEN), specificità (SPE), accuratezza (ACC), precisione (PRE) e punteggio F.
Risultati dei dati classificati
I risultati sono stati ottenuti utilizzando cinque metodi di estrazione delle funzionalità per trovare il set di funzionalità che separa le patch infette con un'alta precisione.
Il set di dati in questo studio è stato formato manualmente ed ha raggiunto una precisione di classificazione del 99,68%, un ottimo risultato, ma sicuramente il metodo proposto dovrebbe essere testato su un altro set di dati di immagini di tomografia computerizzata del coronavirus perché l’aumento della base di dati fornisce ancora maggiore accuratezza ed affidabilità.
I metodi di apprendimento automatico o machine learning, dovrebbero essere implementati maggiormente in ambito medico su immagini addominali TC, toraciche a raggi X, risultati degli esami del sangue ed essere condivisi tra tecnici, medici e scienziati per arricchire la letteratura.
Avere una banca dati anche per il futuro può aiutare tutti nella collaborazione, analisi e valutazione di situazioni come il coronavirus, ma anche nelle attività quotidiane per tumori, malattie genetiche, etc.
Per chi ha voglia e comeptenze in campo medico e di elaborazione dati, può leggere lo studio originale in inglese su cui mi sono basato per questo articolo e dove ho cercato di sintetizzare e semplificare al massimo la terminologia tecnica di una materia complessa, innovativa e per molti ancora sconosciuta come il machine learning, che è invece molto richiesta in tutto il mondo ed anche in Italia, grazie all'ausilio di professionisti dei big data denominati data scientist.
Condividi sui social se pensi che questo articolo sia utile!
![]()
![]()
![]()
Aggiungi Studio Tarantelli al tuo feed di Google News.

27-03-2020
Autore: Mirko Tarantelli - Ingegnere delle Telecomunicazioni - consulente informatico e SEO - Data Scientist
© Tutti i diritti sono riservati. È vietato qualsiasi utilizzo, totale o parziale dei contenuti qui pubblicati.
- La diagnosi del coronavirus con l'aiuto del Machine Learning
- Il sovraccarico dei dati (information overload) statistici nell’analisi dei Big Data
- Sicurezza APP Immuni tra anonimizzazione e pseudonimizzazione
- Come utilizzare i dati aziendali con il Data Mining
- Come utilizzare i dati delle carte fedeltà
- La vendita e monetizzazione dei dati personali
- Come aumentare le vendite con la Data Science
- Come vendere un'auto usata in sicurezza cancellando i dati personali
- Quando i dati personali sono il pagamento di un servizio
- Analisi dei dati: cosa rappresenta e perché eseguirla
- Minimizzazione dei dati: alcuni vantaggi oltre la privacy
